요약 : image를 16x16 patch로 자른 것을 word처럼 생각하고 transformer에 넣어서 학습시킴. 작은 데이터셋에서는 ResNet보다 약했지만, 큰 데이터셋에서는 SOTA 달성함
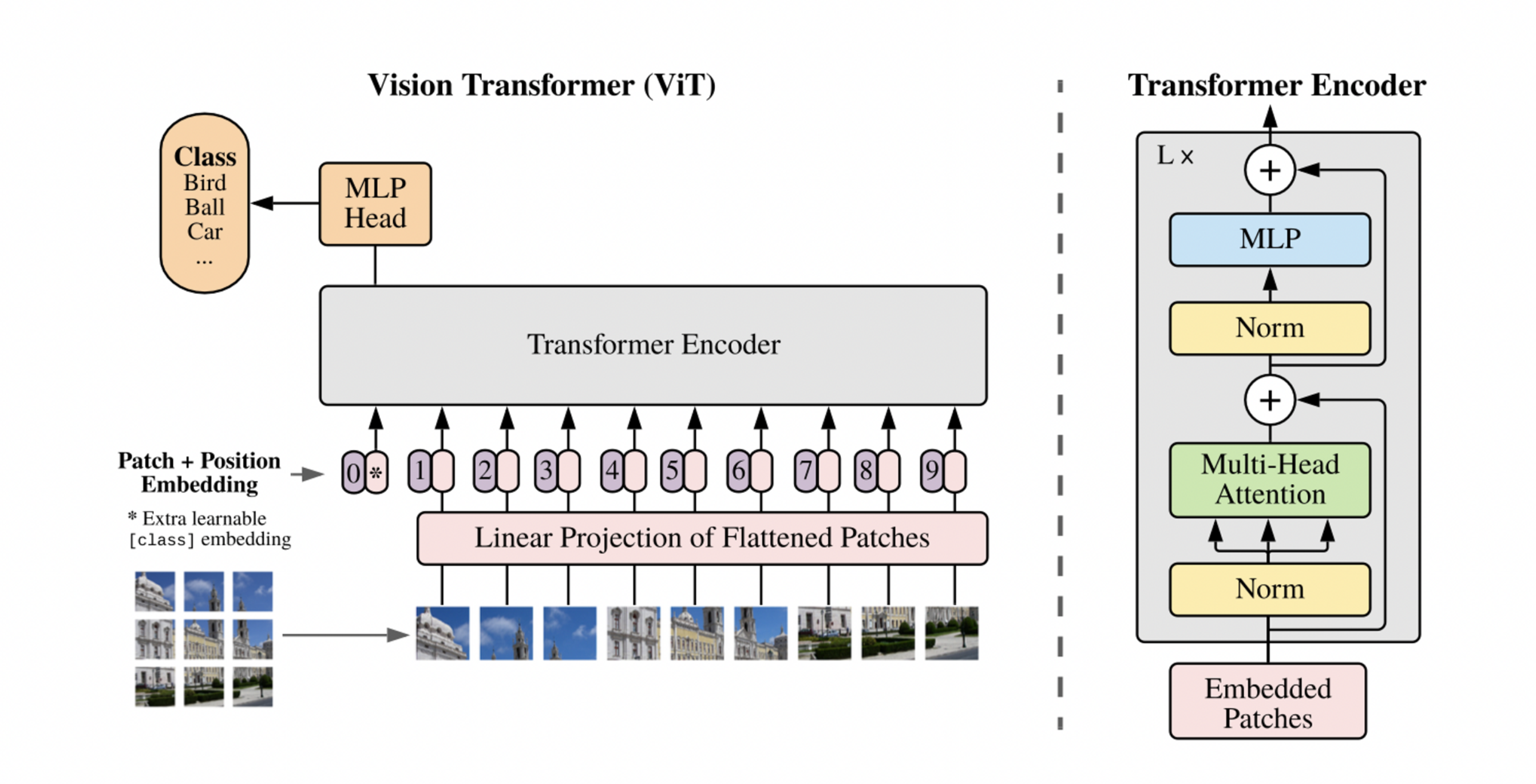
구현
patch 만들기
- image를 patch로 자르기
- $x_p \in \mathbb{R}^{N \times (P^2 C)}~~where~ N=HW/P^2$ → Patch를 flatten
- D dimensional vector로 mapping → 결과물 : patch embeddings
- positional embedding은 learnable 1D vector로 추가해줌
- patch embeddings들의 앞에 learnable “classification token”을 추가해줌 (transformer encoder의 역할은 “contextulaize”이므로, 백지에다가 contextualize 조지면 걔가 class를 의미하게 됨)
Transformer Encoder

- multihead self-attention block 과 MLP block 으로 이뤄짐
- MLP는 Non-linearity를 위해 GELU 사용
- 매 Block 이전에는 Layer Normalization
- 매 Block 이후에는 Residual connections
inductive bias
- 추가적인 가정 이라는 의미
- CNN에서는 positional invariance (translation equivariance)와 spacial locality 라는 inductive bias를 갖고 있음
- ViT에서는 MLP만 local하게 찾고, self attention block은 global하게 찾음.
- 그래서 inductive bias가 훨씬 작다. 좋은건가??!?
'딥러닝' 카테고리의 다른 글
| Fast-RCNN 이해하기 (0) | 2023.06.26 |
|---|---|
| R-CNN 이해하기 (0) | 2023.06.26 |
| StyleGAN v2 이해하기 (0) | 2023.06.26 |
| StyleGAN 개념 (0) | 2023.06.26 |
| Transformer 모델 이해하기 (0) | 2023.06.26 |



