핵심 컨셉 : Region Proposal을 CNN을 통과한 Feature에 대해서만 수행해서 계산량을 줄이자
Single-stage training

Architecture
- image와 regions들을 input으로 받는다
- 원본 image에서 conv feature map을 뽑는다
- 각 region proposal에 대해 RoI pooling layer가 fixed-length feature vector을 뽑음
- RoI pooling layer
- h x w conv feature를 H x W 사이즈로 강제로 변환시킴. H x W 격자를 만들어놓고 거기에다가 각 구역을 maxpooling 한 값을 집어넣음
- RoI pooling layer
- feature vector들은 fc를 통과해서 softmax층 및 bounding box 층으로 나눠서 들어가고, 결과값을 줌 softmax층은 $p_0~...p_K$ 까지 K+1개 class에 대한 확률, bounding box층은 $t^k = (t_x^k, t_y^k, t_w^k, t_h^k)$ 좌표와 크기 정보를 줌
구현
pre-trained ImageNet을 활용
- 마지막 max pooling layer를 RoI pooling layer로 바꾼다
- 마지막 FC와 softmax layer가 softmax와 bounding box regressor로 나뉘어서 동시에 들어가도록 한다
- input을 image 와 RoIs를 받도록 바꾼다
Fine-tuning for detection
RoI는 거의 이미지의 사이즈와 같을 정도로 Receptive field가 큰 경우가 있고, Detection 에서는 모든 RoI proposals들에 대해 conv를 계산해야 하므로 비효율적인 문제가 있었다.
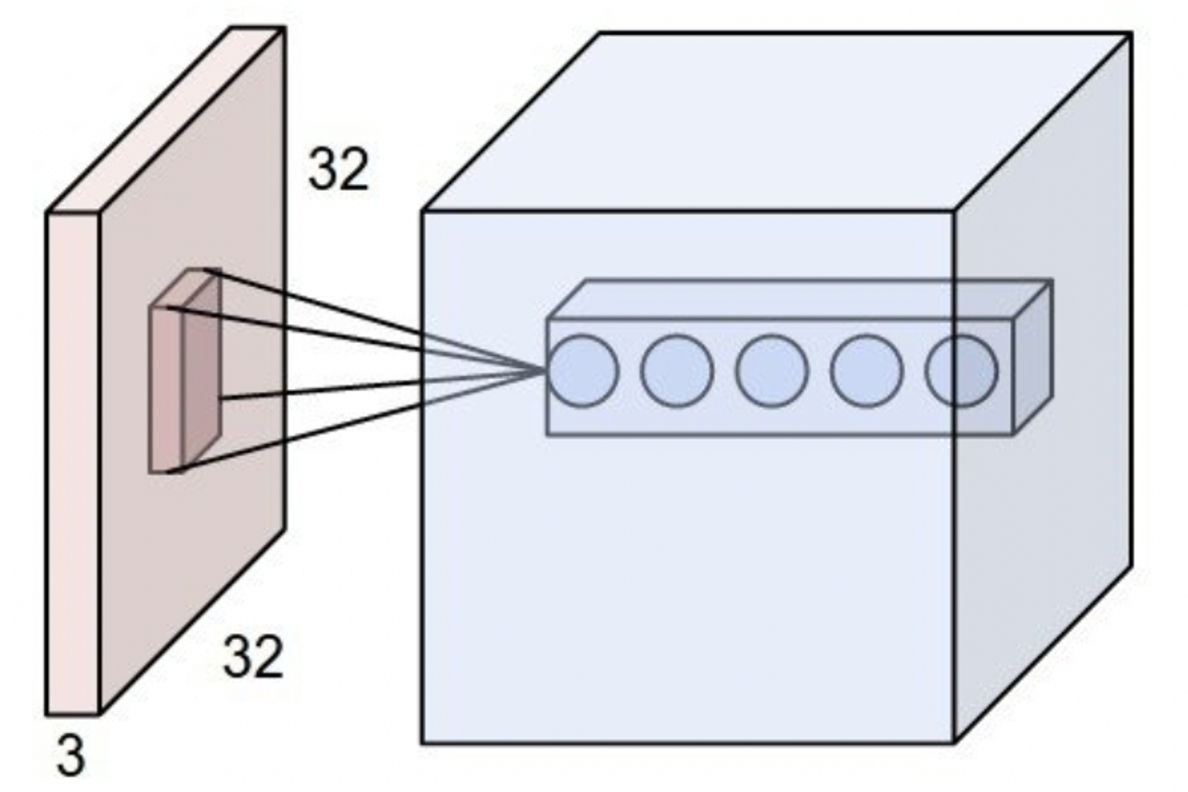
receptive field: 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기
Fast R-CNN에서는 하나의 mini-batch에서는 2개의 이미지에서 각각 64개씩 Region을 뽑아서 넣었는데, 하나의 이미지에서는 forward, backward 에서 메모리를 공유하기 때문에 계산량이 확 줄어든다
Multi-task loss
마지막에 결과값이 softmax랑 bbox regressor 두개에서 나옴. 두개 각각 Loss (cls, loc)를 계산해서 학습에 활용할거임
$u=ground~truth~class,~~v=ground~truth~bounding~box$
u=0은 catch-all background class(감지된 물체 없음)이고, 이때는 ground-truth bbox가 의미가 없으므로 $L_{loc}$ 무시함
$L_{cls}(p,u) = -logp_u$
Mini-batch sampling
Mini-batch 하나당 2개 이미지에서 각각 64개씩 RoI를 뽑는다. 25%는 IoU 0.5 이상인 애들에서(u ≥ 1), 나머지는 IoU [0.1, 0.5) 에서 (u = 0) 뽑는다.
Back-propagation through RoI pooling layers
x 가 RoI pooling layer를 거쳐서 y가 된다.
i*(r,j) 는 maxpooling 결과 index
결국, 선택된 i 에 대해서 더해서 Loss를 만듬
Scale Invariance
brute force
- train, text 모두에서 각 이미지가 pre-defined pixel size로 변환돼서 처리됨
multi-scale approach(pyramid)
- image pyramid를 통해 network에 approximate scale-invariance를 넣어줌
- text time에는 image pyramid가 각 proposal을 scale-normalize하는 데 사용됨
- training time에는 한 이미지가 sampling될 때마다 image pyramid를 random sampling함
Truncated SVD
Detection 문제에서는 FC Layer가 Forward pass 전체의 절반의 시간을 잡아먹어서, 얘를 더 빠르게 바꿔야 함
Truncated SVD 로 FC Layer를 가속화했어염
Architecture
- image와 regions들을 input으로 받는다
- 원본 image에서 conv feature map을 뽑는다
- 각 region proposal에 대해 RoI pooling layer가 fixed-length feature vector을 뽑음
- RoI pooling layer
- h x w conv feature를 H x W 사이즈로 강제로 변환시킴. H x W 격자를 만들어놓고 거기에다가 각 구역을 maxpooling 한 값을 집어넣음
- RoI pooling layer
- feature vector들은 fc를 통과해서 softmax층 및 bounding box 층으로 나눠서 들어가고, 결과값을 줌 softmax층은 $p_0~...p_K$ 까지 K+1개 class에 대한 확률, bounding box층은 $t^k = (t_x^k, t_y^k, t_w^k, t_h^k)$ 좌표와 크기 정보를 줌
구현
pre-trained ImageNet을 활용
- 마지막 max pooling layer를 RoI pooling layer로 바꾼다
- 마지막 FC와 softmax layer가 softmax와 bounding box regressor로 나뉘어서 동시에 들어가도록 한다
- input을 image 와 RoIs를 받도록 바꾼다
Fine-tuning for detection
RoI는 거의 이미지의 사이즈와 같을 정도로 Receptive field가 큰 경우가 있고, Detection 에서는 모든 RoI proposals들에 대해 conv를 계산해야 하므로 비효율적인 문제가 있었다.
receptive field: 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기
Fast R-CNN에서는 하나의 mini-batch에서는 2개의 이미지에서 각각 64개씩 Region을 뽑아서 넣었는데, 하나의 이미지에서는 forward, backward 에서 메모리를 공유하기 때문에 계산량이 확 줄어든다
Multi-task loss
마지막에 결과값이 softmax랑 bbox regressor 두개에서 나옴. 두개 각각 Loss (cls, loc)를 계산해서 학습에 활용할거임

$u=ground~truth~class,~~v=ground~truth~bounding~box$
u=0은 catch-all background class(감지된 물체 없음)이고, 이때는 ground-truth bbox가 의미가 없으므로 $L_{loc}$ 무시함


Mini-batch sampling
Mini-batch 하나당 2개 이미지에서 각각 64개씩 RoI를 뽑는다. 25%는 IoU 0.5 이상인 애들에서(u ≥ 1), 나머지는 IoU [0.1, 0.5) 에서 (u = 0) 뽑는다.
Back-propagation through RoI pooling layers

x 가 RoI pooling layer를 거쳐서 y가 된다.
i*(r,j) 는 maxpooling 결과 index
결국, 선택된 i 에 대해서 더해서 Loss를 만듬
Scale Invariance
brute force
- train, text 모두에서 각 이미지가 pre-defined pixel size로 변환돼서 처리됨
multi-scale approach(pyramid)
- image pyramid를 통해 network에 approximate scale-invariance를 넣어줌
- text time에는 image pyramid가 각 proposal을 scale-normalize하는 데 사용됨
- training time에는 한 이미지가 sampling될 때마다 image pyramid를 random sampling함
Truncated SVD
Detection 문제에서는 FC Layer가 Forward pass 전체의 절반의 시간을 잡아먹어서, 얘를 더 빠르게 바꿔야 함
Truncated SVD 로 FC Layer를 가속화했어염
'딥러닝' 카테고리의 다른 글
| Stable Diffusion (0) | 2023.06.27 |
|---|---|
| REGULARIZED AUTOENCODERS FOR ISOMETRIC REPRESENTATION LEARNING (0) | 2023.06.26 |
| R-CNN 이해하기 (0) | 2023.06.26 |
| ViT (Visual Transformer) 이해하기 (0) | 2023.06.26 |
| StyleGAN v2 이해하기 (0) | 2023.06.26 |


